Introducing TinyFlux: The Tiny Time Series Database for Python-based IoT & Analytics Applications

While datasets come in a nearly infinite number of shapes and sizes, the same cannot be said for data stores. Sure- any great piece of software should be able to handle a range of use-cases from small to large, but between bare-bones text files and unwieldy standalone database servers there exists a lack of options for querying and storing data in a user-friendly way.
TinyDB by Markus Siemens, however, wonderfully occupies this niche in the Python ecosystem for document-like datasets. TinyDB is a lightweight, open-source Python package that provides the API and functionality of a document-oriented datastore with the simplicity of flat, human-readable files. If your dataset can be represented as key/value pairs and you won’t be working with gigabytes of data in a distributed manner, TinyDB is a stellar package that you can integrate into your Python workflow as a bonafide database in mere seconds.
One of TinyDB’s greatest strengths (as well as one of its greatest limitations) is that it is backed in most of its use-cases by the JSON file format. Human-readability, cross-platform interoperability, and a semblance to Python’s dictionary object are all great benefits of JSON, but due in part to its syntax rules (the need for enclosing brackets, braces…), the file — and by proxy, the database — cannot be appended to without repeatedly reading the entire database into memory, making writes an increasingly costly operation.
As a software engineer that works often with IoT sensor data (and a hobbyist Arduino programmer that works solely with IoT sensor data), I often have a need to work with timestamps as well as to perform high-frequency writes. These are core features of time series data and while TinyDB is versatile, it is not designed for this kind of dataset- one in which keys are timestamps, observations must be sorted, and writes occur much more frequently then reads (often at a high frequency).
It is for this reason that I designed TinyFlux upon the same pillar as TinyDB, while prioritizing for time series datasets. Like TinyDB, it is lightweight, contains an ORM-like query syntax, is backed by a text file (CSV in this case), allows for flexible schemas, and is fun to use. Unlike TinyDB, timestamps are first-class data types (specifically, the tricky Python datetime object) and the time it takes to perform writes never increases, regardless of the size of the underlying file.
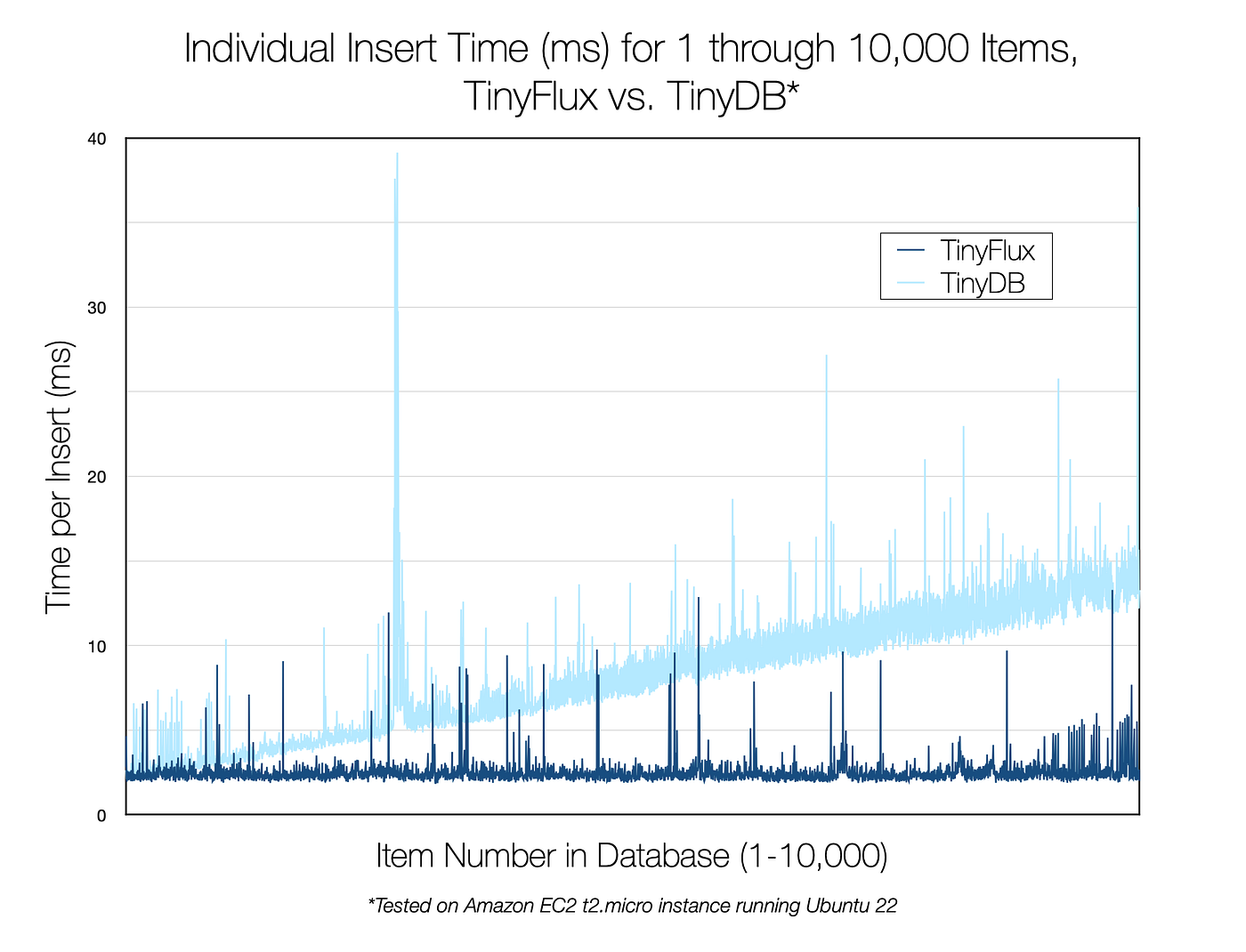
To be sure, TinyDB has and will continue to have its place as a fun, easy-to-use database for document-like data (I currently use it in Dash applications for server-side user configuration). TinyFlux merely attempts to do for time series datasets what TinyDB already does for document-like datasets.
The “Flux” in TinyFlux: Integrating Time Series Concepts from InfluxDB
As of this writing, InfluxDB is among the most mature time series databases used in production. If you a need distributed, production-ready database for your high-frequency time series data, you’d be hard-pressed to find a reason to not consider InfluxDB (my teams have used it in several applications in which we need to analyze 10,000+ Hz embedded sensor streams and it performs quite well).
Performance aside, its key concepts and first-class objects specifically describe the components of a time series dataset (as opposed to say, a generic columnar dataset) leading to a pragmatic and logical query language that is no longer SQL, but is familiar enough for users to learn and use quickly in time series contexts. For this reason, TinyFlux borrows the key concepts and objects of InfluxDB for its own syntax, hence the -Flux suffix of the TinyFlux moniker.
As a quick illustration, the insert snippet below demonstrates how a “point”—one of the most important concepts in InfluxDB — is integrated into TinyFlux. A Point in InfluxDB is just an individual observation in a time series signal (akin to a “row” in a relational database), and it contains:
- A timezone-aware timestamp
- Numeric key/values known as fields
- Textual key/values known as tags
Fields and tags are treated differently when it comes to indexing, sorting, and querying and thus they are separate but similar concepts.
On the retrieval end, TinyFlux’s query language simply extends that of TinyDB to handle time series data, as in the instance of querying by timestamp:
By combining the simplicity of TinyDB with the concepts of InfluxDB, TinyFlux represents the middle ground in time series data stores in which you can enjoy the streamlined API of a mature database interface without the need for provisioning and maintaining new instances to host your data. It is nice to know that if you become a user of TinyFlux and you do indeed find yourself outgrowing the use-case that TinyFlux was designed for, a natural evolution is just an easy transition to InfluxDB away.
Getting Started with TinyFlux
Think TinyFlux is for you? Head over to the GitHub repository. TinyFlux is easily installed using PyPI (e.g. pip install tinyflux) and has been thoroughly tested on all modern versions of CPython (3.7 to 3.10) and PyPy 3.9.
Need some inspiration? Below are a couple of Jupyter Notebooks containing examples of two common use-cases of TinyFlux:
Finally, TinyFlux may not be for you- not everyone is analyzing time series data using Python (heathens!). However, if you feel like it could potentially be of use to somebody somewhere, please give the project a star on GitHub! I’ll buy you a drink and talk data with you if our trajectories ever cross in the future 🤞.
TinyFlux is currently in beta and welcoming any and all contributions/feedback. If you would like to contribute to TinyFlux, check out the README in the repository. Anything else? Drop me a line.





